


XGBoost Made Me.
XGBoost is arguably the smartest machine learning model in the world. I can confirm.

Disclaimer/Update: Finance articles will be resuming, the betting algorithm was my main focus for a bit, but it is now complete, so we will get back into the weeds of some super interesting finance developments.
To quickly recap, we’ve been using machine learning to predict whether or not an event will occur, and then placing wagers on said prediction. In our case, we’ve been using linear and logistic regression algorithms to get there, but unbeknownst to me, there is a model type that is easy-to-access, and blows laps around standard regression.
In just a moment, you’ll see just how significantly the model upgrade improves profitability, but first, we need to take a look at how it works:
Gradient Boosting; What Even Is It?
XGBoost stands for Extreme Gradient Boosting, which is a bit more simple than it sounds. “Boosting”, as the name implies, is the process of increasing the power/accuracy of a model by combining it with other models. This is done by first building out prediction “trees”. We’re working with baseball data, so let’s see an example of that:
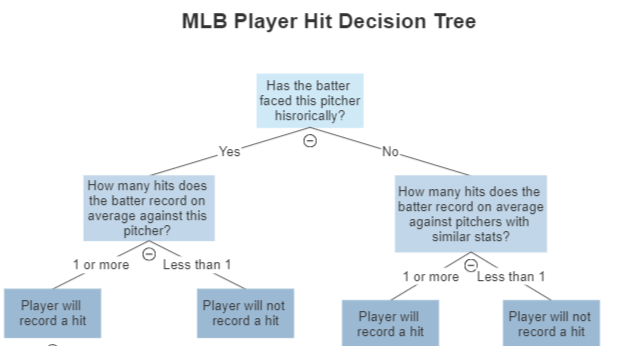
This represents just one tree, but this is done iteratively to cover all possibilities (based on our provided data), like: “Does the batter play for the New York Yankees?”, “Is the game temperature greater than 75 degrees?”, “Is the batter name Bo Bichette?”, etc.
When a tree model is finished, it returns an output that describes how well that tree model predicted the target. The most important output is the “residual”, which is essentially just the average error. For example, if our above tree model predicts a player to get 1 hit, but that player gets 0, then the residual is 1 (predicted - actual). Higher residual values indicate model inaccuracy.
Once this residual is gathered from the first tree, it is saved and “remembered” to train the next tree. For example; if the tree knows that voting “yes” when a batter faces a debut pitcher leads to higher residuals, it will factor that into the next tree. In the next tree, if a batter faces a debut pitcher, the new tree would put the probability of a “no” higher; quite literally a machine, learning.
This remember-and-improve approach is done iteratively until the residual is the lowest value that it can be. This iterative process is known as gradient descent:

Well, What’s The Extreme Part?
The “extreme” in XGBoost comes from the rather, well, extreme performance enhancements. The typical gradient boosting algorithm is known as a GBM (“gradient boosting machine”), and as you can imagine, building out those trees and residuals were incredibly slow and/or resource intensive. XGBoost adds performance enhancements to this such as testing trees in parallel, using CPU cache to store residuals, and a few other techy-related boosts which can be found here.
From Model to Profit
Picking up from the last update, we used PyCaret to easily train the models and initially went with linear regression as our choice; let’s take a look at the model stats:

The main statistic to focus on is the “MAE”, which represents the mean average error. To interpret this, it is essentially saying that the realized label (what actually happens), tends to be about 0.71 points away from the prediction. So, if the model estimates a player to get 2 hits, on average the real number will be 1 hit or 3 hits (+/- 0.71 (round to 1)).
We want to minimize this number as much as possible, and luckily, we can just as easily train an XGBoost model to see if we’ll find an improvement:
Keep reading with a 7-day free trial
Subscribe to The Quant's Playbook to keep reading this post and get 7 days of free access to the full post archives.