
Primitive Quant Sports Betting: NBA Edition [Code Included]
Last time, beating the casino took pitch-perfect models and record amounts of time. What if we tried something simpler?

Here at The Quant’s Playbook, we’ve had a long, off-and-on again relationship with quantitative sports betting. It’s only natural due its intrinsic connection to our main business — using data to make profitable predictions on future outcomes.
What started off as a quest to annihilate the casinos has acquiesced into multiple ways of sort of beating the books. So far, we’ve built a model and strategy for every single major sport in their respective seasons, as demonstrated in our hallmark: Machine Learning for Sports Betting: MLB Edition, but we haven’t quite gotten to the NBA yet.
The regular season for this year goes from October 24, 2023 – April 14, 2024, so we’re a bit late, but there’s still 3 months left to squeeze out some juice from these markets. But before diving in, we’ll need some inspiration from what‘s worked for us in the past.
Not So Random Forests
Our historical approach was simple and beautiful:
First, we got data on everything we could; what every player did, where the team played, what temperature the game was played at, the wind speed — everything.

From this dataset, we fed it into a random forest model to get predictions for different variables (e.g., touchdowns, total yards, home runs, etc.). We prefer random forest models for a few reasons:

Pictured above is one sample random forest tree that uses 3 features to predict the price of a house; the square feet, the number of bedrooms, and the number of bathrooms. This tree will use the output of all the nodes (branches) to create a prediction. We create 100 trees just like this, all using a different subset of data and features to create multiple, averaged predictions that are very robust to issues like overfitting.
We assumed our model was the most accurate, so we began searching for bets where we would have an edge. For example, if our model estimated a 65% chance for Player A to record a strikeout, but DraftKings priced in a 55% chance, this would be a 10% edge.
For MLB, we found an edge on a pure odds basis (book implied probability lower than our model’s):


Then, with the NFL, we found an edge on a line-basis. Essentially, picture a sports market for how many yards an NFL player will record in a game. Generally, the line is Over/Under X, with X being the theoretical expected value. So, if DraftKings set the line for Player A at Over/Under 25 yards, but our model expected player A to have a baseline value of 35 yards, we would have a 10 point edge since the line should theoretically be set at 35 yards instead of 25:
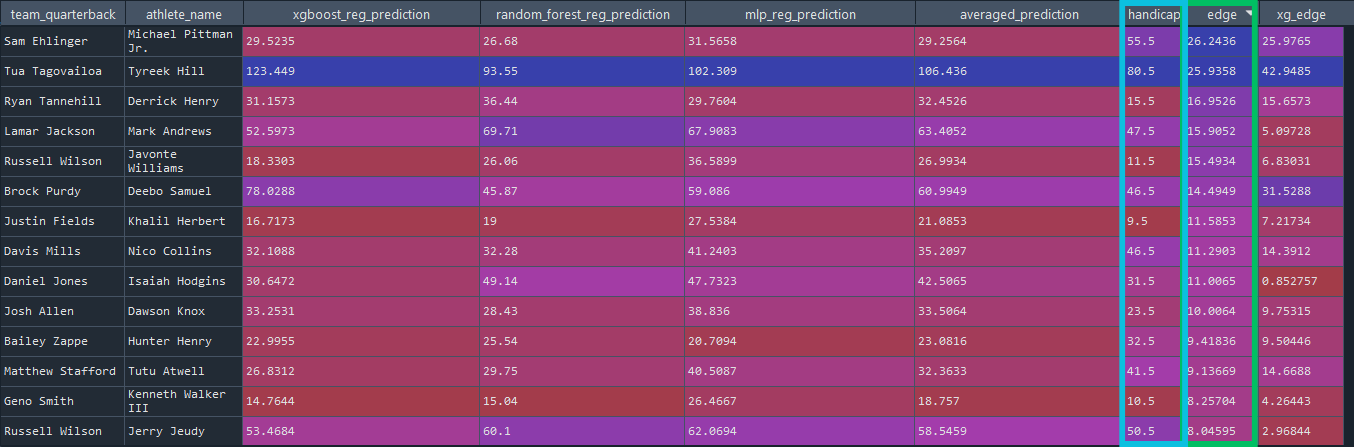
These experiments all went well, but they led us to a key realization:
The sportsbook tends to do all of the work for us.
More often than not, even our most advanced model predictions tended to mirror those offered by the sportsbook. For instance, on a typical strip of NFL prop markets, 80% of our predictions would be the same as what’s listed on the sportsbook. This makes sense, considering that the models used by the books are based on the same historical public data, albeit with a touch of proprietary insight on the occasional odd line.
Not only that, but more often than not, our models and those odds were generally pretty accurate. If we (book and model) arrived at a 60% probability, that bet would win ~60% of the time.
So for this NBA season, perhaps it makes sense to try something a bit more… primitive.

Could It Really Be That Simple?
Keep reading with a 7-day free trial
Subscribe to The Quant's Playbook to keep reading this post and get 7 days of free access to the full post archives.