


Making Money with Synthetic Data and Milk Futures
Even as a quant, sometimes you have to get your hands dirty.

Commodities are a fascinating product and are the quantitative traders’ dream — they move for clear, predictable reasons and when they trend, they trend hard.

For that reason, trend following is one of, if not the most, dominant set of strategies used in commodities and futures trading. However, it’s kind of a black box.
Yeah, we know that, at core; a long signal is generated by some moving average crossover, then the trade is exited when that signal goes away. Do this across a portfolio of 20 different commodities rebalanced monthly and you get performance like this:
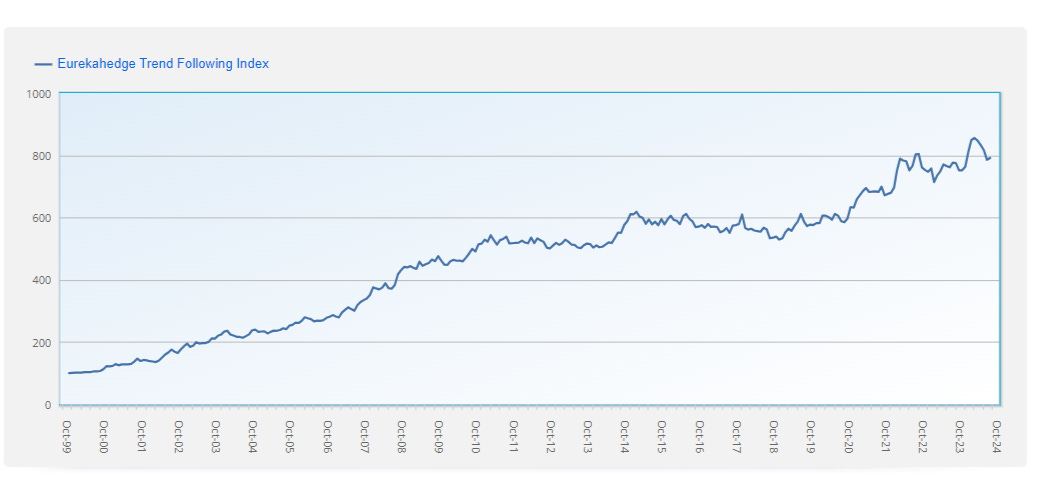
But what exactly does that mean? What are the optimal historical periods for the averages? What methods are there for testing whether a trend is actually a trend or just a spurious movement? How do you know if your chosen moving average period isn’t just overfit to that commodity and will work in others and/or in the future?
These are serious questions that need serious answers, so if we’re going to take a stab at this, we’ll want a more systematic and reliable way of detecting trends.
Naturally, we can train a machine learning model to do exactly that.
This way, we can have the control and precision of only taking trades when our model gives the go ahead and taking action off the table when our model says to pull back. In theory, this should provide more stability than a traditional rules-based approach.
However, there’s a slight problem.
Traditionally, we would train the model on the historical data of the respective asset and use that to predict what might happen.
Our goal is to run this across a wide variety of commodity products which all behave differently — a trend in copper futures might look very different than a trend in, say, orange juice futures.
Just take a look at a comparison of the two’s time series:
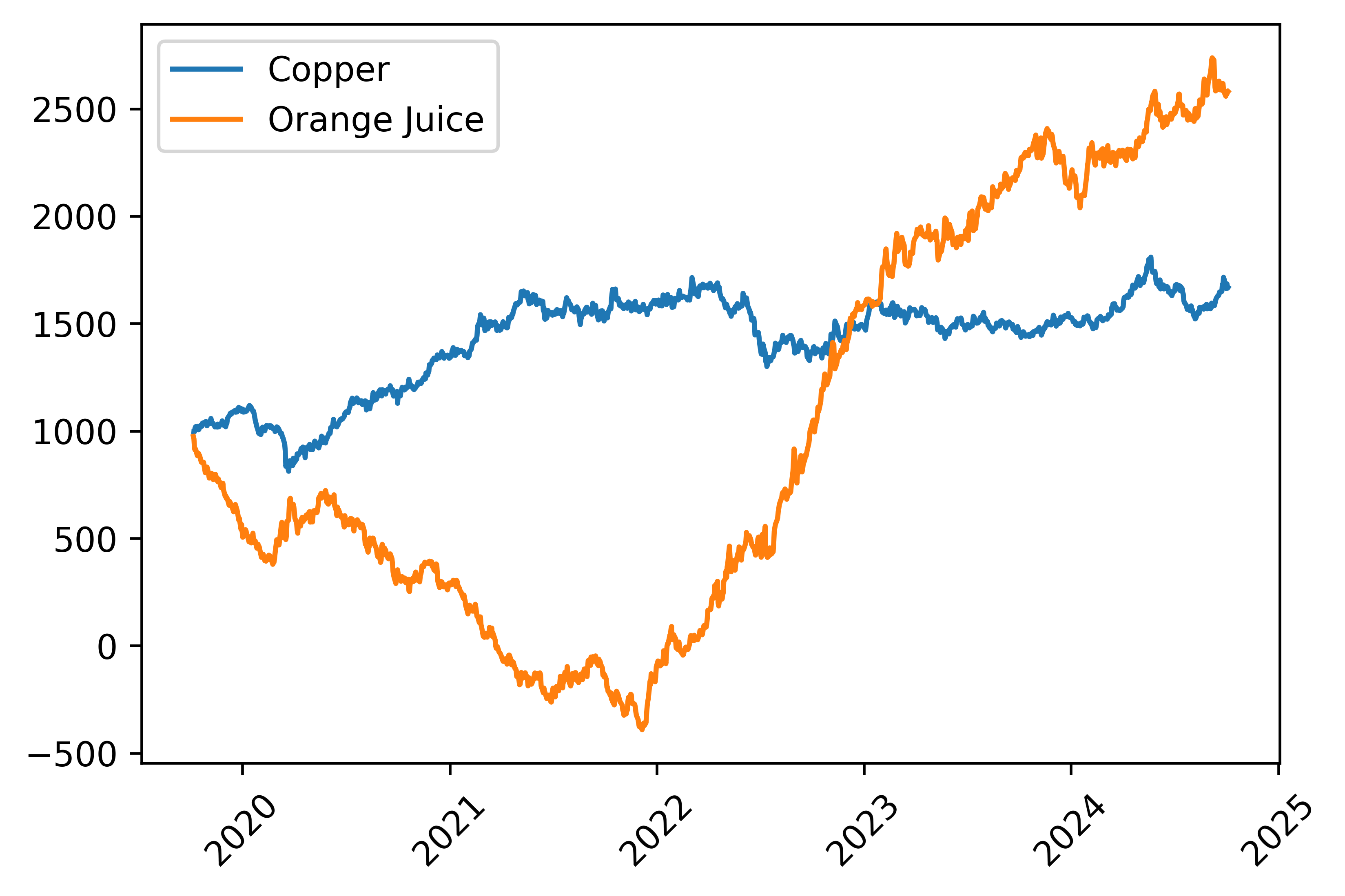
We could, in theory, just train a model for each individual futures product, but this adds significant complexity and leaves us prone to overfitting to historical periods.
So, if we want to build a model that works well across multiple assets, we’ll have to think outside the box and try something new.
The Synthetic Data Edge
When we model something, we’re essentially saying, “Okay, here’s what the relationship between prices looked like in the past, try to see if you can spot those relationships repeating in this out of sample data.”
So, what if – now, just hear us out.
What if we just created the ideal dataset, trained our model on those ideal relationships, and then let it spot them in out of sample data?
That might sound a bit confusing, so let’s break that down:
Our mission is to detect when an asset is trending and when that trend is over.
We can manually create a dataset where we explicitly design it such that when feature_1 is above 0, the is_trend target will be a 1 — if it’s below 0, the is_trend target is set to a 0.
Once the model is trained on that “fake” dataset, we let it predict on out of sample data. If, for instance, the feature_1 for natural gas on 01/01/2025 is above 0, the model will output a 1, indicating an active trend.
So, we’re essentially saying: “In a perfect world, a trend will look like this. Go out and see if you can spot that in this new dataset”.
Doing this comes with a few potential advantages:
We greatly, if not totally, reduce the risk of overfitting.
In this case, we mean overfitting as in: “the model is very good at predicting natural gas trends when it uses data specifically from March 2019 to February 2021.”
Since the data isn’t even “real”, we’ll get a fairer, absolute sense of how strong our features are as opposed to how well they performed over specific periods using data from other specific periods.
We can test over substantially longer periods across significantly more assets
Since we no longer have to worry about training on say, 252 days of historical data, we can get point-in-time predictions by just passing in the features of that day.
Just seeing the performance on an extra 252 days (1 full market year) goes a long way in evaluating the efficacy of our approach.
So, let’s give it a shot.
To begin, we’ll first create our features.
We know that at the core of trend following is a moving average, so we want a measure of how far the current price has diverged from its historical average. For instance, if Live Cattle Futures are suddenly 10% higher than its 1-month average price, it might be the harbinger of a trend.
So, that divergence will be our first feature.
Now, we don’t want too many false flags, so we want to also compare today’s divergence to yesterday’s — if yesterday there was a +5% divergence, and today there’s only a +2% divergence, we want the model to know that this is likely not indicative of a booming trend.
So, we create another feature which is just the lagged divergence.
Finally, there’s a “little” known market phenomena that might give us a bit of juice:
The 52-Week High Effect
This effect essentially states that the closeness of a stock to its 52-week high leads to predictably higher returns in the short-term. The rationale for this roots largely from behavioral finance:
Anchoring Bias: Investors often use the 52-week high as an “anchor”, a reference point for judging a stock's future potential. When prices approach and/or surpass this level, investors may interpret it as a signal of strength, pushing prices even higher as more buyers jump in.
Herding Behavior: When a stock reaches a 52-week high, it garners attention, leading other investors to follow the trend, assuming that the market has positive information about the stock.
Confirmation Bias: Investors who already own the stock may use this recent high as a confirmation of their original conviction/thesis and buy more shares.
Loss Aversion: The 52-week high serves as a psychological barrier. Investors who were hesitant to sell before may sell less when prices exceed this point, as they want to avoid missing out on potential gains. This reduced selling pressure contributes to continued price appreciation.
Here’s a few papers on the subject:
Now, applying this to commodities is a bit tricky since sometimes a 52-week high won’t repeat — for instance, if in 2020, green lumber futures reached a high of $1,000 because of a major forest fire, that would be a poor reference point to use on a forward basis.
So, we can go with something a bit shorter, like the distance from the 3-month high. We’ll also add the lagged distance like we did for our first features (how far from the high it was yesterday).
Once we’ve conceptualized the features we’ll use, we can then build the dataset.
Now, we’re sure that there’s a sophisticated, Pythonic way to create a dataset like this, but after an hour of frustratingly fiddling around with numpy, we just ended up building it by hand in Excel — looks like there’s still some value in the old-fashioned ways after all.
Here’s what this dataset looks like:

An eye sore? Yes, but as demonstrated, when the price is getting closer to setting a new high and its divergence from the average is increasing, we let the model know: “this is what a trend looks like” (trend = 1).
Considering that the relationship is so clearly defined, we really only need 25 rows to act as the training set. Since it’s a small, simple dataset we'll go with a logistic regression model.
Can This Thing Actually Work?
To test if this will work, we’ll run our typical walk-forward testing.
So, each trading day, we’ll pass to our model just the data available that day — notably, the % divergence from the average price (1-month), the % distance from the prior high (3-month high), and the lagged values of each.
If our model predicts a 1, it is essentially saying to us: “this is a trend.”; for a 0, “this is not a trend.” We are only passing in 1 day at a time, so each prediction is what we would’ve actually seen on that given day.
So, let’s see how it did:
Keep reading with a 7-day free trial
Subscribe to The Quant's Playbook to keep reading this post and get 7 days of free access to the full post archives.